Python_Unicode字符机制解析
前言
在查阅一些师傅的文章后,我发现很多师傅的文章都把 python 的 Unicode 字符解析机制与 flask 或 bottle 等 Web 框架联系在一起。其实不然,这反而是 python 本身的一种特性。这一特性对Web手们可能很熟悉,但是对于其他人,甚至 python 开发者,甚至 ai 都不是很清楚。
那么我就在这篇文章中简单探求一下python这个小特性的背后原理。
问题引入
猜猜这四行python代码会输出些什么?
1 | |
他们输出了:
1 | |
没错,即使肉眼上看上去不同,python在字符串比较上也能知道ᵖrint和print是不同的。但是ᵖrint在作为函数使用时、在判断 print 函数是否与其是同一个对象时、在查询其类型时,都与python的内置函数print一般无二。
那么,为什么在作用上python会把ᵖrint当做print来用呢?
查阅资料
在查阅python官方文档后,我找到了答案:https://peps.python.org/pep-3131/
世界上许多人编写 Python 代码,他们不熟悉英语,甚至不熟悉拉丁书写系统。这些开发者通常希望用他们的母语定义类和函数的名称,而不是为他们想要命名的概念想出一个(通常不正确的)英文翻译。通过使用母语标识符,可以提高该语言使用者之间的代码清晰度和可维护性。
有些语言存在通用的音译系统(尤其是以拉丁语为基础的书写系统)。而另一些语言的用户使用拉丁语书写母语词汇则面临较大困难。
在这个问题的基础上,特殊字符的处理方法出现了,python的解决方法是:
The following changes will need to be made to the parser:
- If a non-ASCII character is found in the UTF-8 representation of the source code, a forward scan is made to find the first ASCII non-identifier character (e.g. a space or punctuation character)
- The entire UTF-8 string is passed to a function to normalize the string to NFKC, and then verify that it follows the identifier syntax. No such callout is made for pure-ASCII identifiers, which continue to be parsed the way they are today. The Unicode database must start including the Other_ID_{Start|Continue} property.
- If this specification is implemented for 2.x, reflective libraries (such as pydoc) must be verified to continue to work when Unicode strings appear in
__dict__slots as keys.
翻译一下:
- 如果在源代码的 UTF-8 表示中发现非 ASCII 字符,则进行正向扫描以找到第一个 ASCII 非标识符字符(例如空格或标点符号)。
- 整个 UTF-8 字符串会被传递给一个函数,该函数会将字符串规范化为 NFKC 格式,然后验证其是否符合标识符语法。纯 ASCII 标识符则不会进行此类调用,因为它们仍按目前的方式进行解析。Unicode 数据库必须开始包含 Other_ID_{Start|Continue} 属性。
理解
OK原来是这样,python官方还是很人性化的,为了全世界的人们都能使用python编程,创造出了这个办法。只要你输入的非 ASCII 字符存在于 python 的 Unicode 数据库,那么就会有一个函数会将该字符规范化为 NFKC 格式,以便后面的使用。
所谓的“一个函数”,这个”函数”指的是 Python 解释器在词法分析(lexical analysis) 阶段内部调用的规范化处理机制。这个过程主要由 Python 的解释器核心实现,并不是一个直接暴露给用户的独立函数。官方文档里并没有列出来,但是我还是找到了一个类似作用的方法,就是 unicodedata 库的 normalize 方法:
1 | |
上面的代码会输出:
1 | |
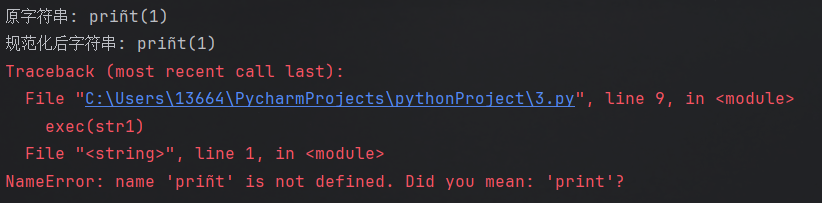
如果你输入的字符过于 “特殊”,不存在于python 的 Unicode 数据库里,那么就会转化失败:
1 | |
这段代码会报错:
运用
假设有这样的一段代码:
1 | |
这里不允许[a-zA-Z]的字符出现,那么就可以特殊的 unicode 字符解析特性绕过:
1 | |

ok,那又有小伙伴说了,这么多特殊字符我去哪找呢?找到了一个一个替换多麻烦?
可以用这个网站来查询:https://www.compart.com/en/unicode/
我也在这里给大家准备了脚本:
1 | |
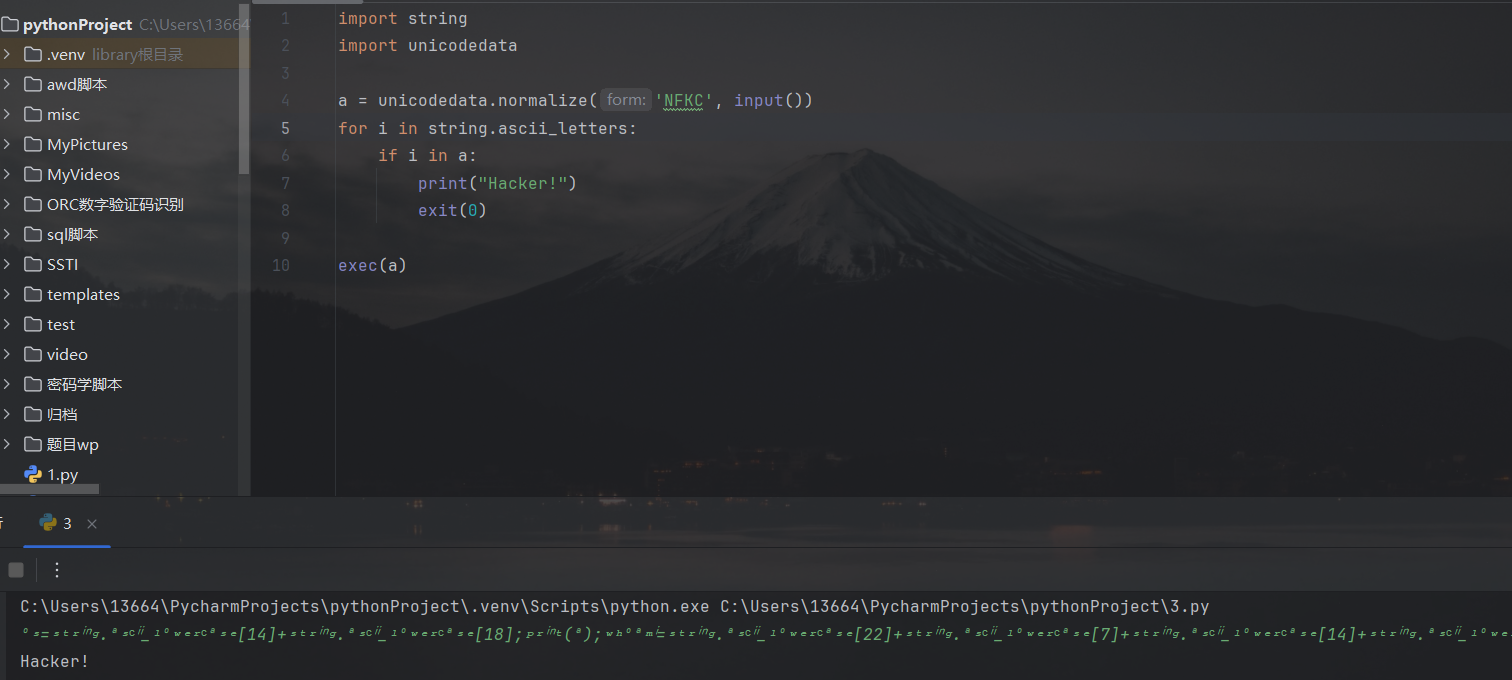
如果出题人不想让别人使用这个特性,只需要使用unicodedata.normalize方法来规范化一下用户的输入即可:
1 | |
最后,如果师傅们有任何问题,欢迎加我社交账号,与我一起探讨!